本文来自《DSFD: Dual Shot Face Detector》,时间线为2018年10月,是南理工Jian Li在腾讯优图实验室实习时候的作品。在WIDER FACE,FDDB上效果也超过了PyramidBox和SRN。
0 引言
最近在比赛上拿到最好成绩的人脸检测模型大致可以分成2类:
- 基于RPN的网络,这种网络是2阶段模型
- 基于SSD这种一次shot检测,直接预测边界框和置信度。
而一次shot的检测器因其高预测速度和简单的系统设计而更受青睐。不过分析下来,仍然有以下三个问题未完全解决:
- 特征学习:当前特征金字塔网络(feature pyramid network,FPN)广受应用,然而FPN只是将high-level和low-level的输出网络层简单合并了下,并未考虑到当前层的信息,而且基于锚之间的上下文关系信息都被忽略了;
- loss设计:主流使用的是目标检测中传统的loss函数,为了解决类别不平衡问题,Focal loss可以重点关注一个稀疏的硬样本的训练。为了使用所有原始和增强的特征,《Feature agglomeration networks for single stage face detection》提出层级loss以更有效训练网络。然而上面这些loss函数都没考虑到feature map在不同level上需要渐进学习的能力; ps:平滑L1 loss有助于阻止梯度爆炸;
- 锚匹配策略:基本上,每个feature map上面的预定义锚集合是通过在图片上平铺不同尺度和长宽比的框完成的。许多别人先前的工作分析了锚的合理尺度和锚的补偿策略,以此来增加正锚的数量。然而这些策略忽略了数据增强中的随机采样。人脸尺度的连续性和大量不同尺度的锚仍然会导致负锚和正锚之间比例的差距
本文提出了一个新的人脸检测框架叫DSFD(dual shot face detector),其继承了SSD的结构:
- 首先,结合PyramidBox中low-level的FPN与RFBNet中的感受野块(receptive field block,RFB),提出一个特征增强模块(feature enhance module,FEM)来增强特征的判别性和鲁棒性;
- 其次,受到《Feature agglomeration networks for single stage face detection》中层级loss(hierarchical loss)和PyramidBox中的金字塔锚的启发,将更小的锚平铺到higher-level feature map cell上可以获得更多关于分类的语义信息和更多关于检测的高分辨率定位信息。提出渐进锚loss(progressive anchor,loss,PAL),通过一组更小的锚去计算辅助有监督loss,以辅助特征学习;
- 最后,提出一个改进锚匹配方法(improved anchor matching,IAM),在DSFD中融合锚划分策略和基于锚的数据增强方法去,以提供更好的回归器初始化,让锚和ground-truth人脸尽可能匹配。

1 结构
1.1 DSFD的结构(Pipeline of DSFD)
DSFD的结构如图2。
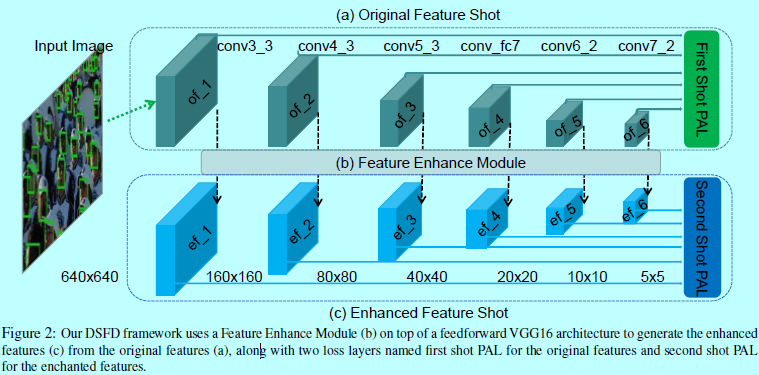
1.2 特征增强模块(Feature Enhance Module)
这里提出的FEM模块主要是为了增强original features 让特征变得更据辨识性和鲁棒性。对于当前锚\(a(i,j,l)\),FEM会利用包含当前层锚\(a(i-1,j-1,l)\),\(a(i-1,j,l)\),...\(a(i,j-+1,l)\),\(a(i+1,j+1,l)\)和上层锚\(a(i,j,l+1)\)的不同维度信息。具体的,关联锚\(a(i,j,l)\)的feature map cell可以通过数学定义:
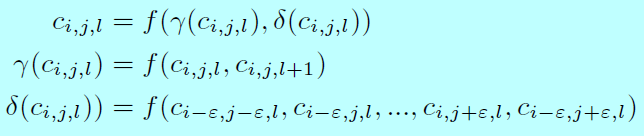
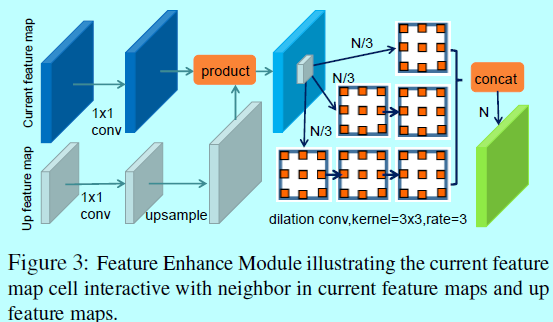
- 首先用1x1卷积核去归一化feature maps;
- 然后,上采样上一层feature maps并与当前层进行逐元素相乘;
- 最后,将feature maps划分成3个部分,并连接对应的3个子网络,每个子网络包含不同数量的扩张卷积层。
1.3 渐进锚loss(Progressive Anchor Loss)
DSFD采用的是多任务loss,因为其可以让original和enhanced feature maps的训练任务以两个shots进行训练。首先,DSFD的second shot anchor-based 多任务loss函数定义如下:
\[L_{SSL}(p_i,p_i^*,t_i,g_i,a_i)=\frac{1}{N}(\sum_iL_{conf}(p_i,p_i^*)+\beta\sum_ip_i^*L_{loc}(t_i,g_i,a_i))\] 这里\(N\)是匹配的密集边界框的个数;\(L_{conf}\)是基于2个类(人脸和背景)的softmax loss;\(L_{loc}\)是基于锚\(a_i\)下,介于参数化的预测边界框\(t_i\)和ground-truth边界框\(g_i\)之间的平滑L1 loss;当\(p_i^*=1(p_i^*=\{0,1\})\)时,锚\(a_i\)是正类,且此时位置loss也是激活的。\(\beta\)是一个权衡这两个loss的超参数。相比于同一个level中的enhanced feature maps,original feature maps针对分类的语义信息更少,但是有更多针对检测的高分辨率定位信息。因此,作者认为original feature maps可以检测和分类更小的人脸。因此,作者提出了基于一组更小锚的first shot 多任务loss:\[L_{FSL}(p_i,sp_i^*,t_i,g_i,sa_i)=\frac{1}{N}(\sum_iL_{conf}(p_i,sp_i^*)+\beta \sum_ip_i^*L_{loc}(t_i,g_i,sa_i))\] 这两个shot loss可以组合成一个渐进式锚loss:\[L_{PAL}=L_{FSL}(a)+L_{SSL}(sa)\] 这里first shot中锚的size是second shot中的一半。在预测阶段,只采用second shot的输出,这意味着预测阶段并不会有额外的计算代价。1.4 改进的锚匹配策略(Improved Anchor Matching)
在训练中,需要计算正锚和负锚以决定对应人脸边界框是哪一个锚。当前锚匹配方法是基于锚和ground-truth人脸之间双向选择。因此锚的设计和增强的人脸采样是协同的,以此尽可能让锚和人脸进行相配,以此提供回归器更好的初始化。

- 基于\(\frac{2}{5}\)的概率,采用PyramidBox中data-anchor-sampling相似的基于锚的采样,其是在一个图片中随机选择一个人脸(裁剪的子图片包含人脸),并将子图和选择的人脸之间size比例设置为\(\frac{640}{rand(16,32,64,128,256,512)}\);
- 基于\(\frac{3}{5}\)的概率,采用SSD中的数据增强方法。
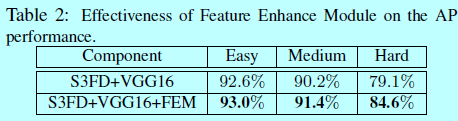
2 实验结果分析


.